
Durante años, la tecnología de asistencia visual ha avanzado impulsada por dos motores principales: un incremento constante de la potencia de cálculo y algoritmos cada vez más precisos. Sin embargo, ese progreso técnico no siempre se ha traducido en una adopción real por parte de las personas ciegas. Muchos sistemas prometedores han quedado confinados al laboratorio o a la demo espectacular por una razón tan simple como incómoda: no estaban pensados para cómo aprende, se mueve y percibe un ser humano real.
Frente a ese enfoque tecnocéntrico surge una investigación que merece una atención especial. En abril de 2025, la revista Nature Machine Intelligence publicó el trabajo “Human-centred design and fabrication of a wearable multimodal visual assistance system”, liderado por el grupo del profesor Leilei Gu desde la Shanghai Jiao Tong University, en colaboración con varias instituciones punteras de China y Hong Kong. Es importante subrayar que lo que presenta este artículo es una investigación desarrollada íntegramente en un entorno de laboratorio, basada en dispositivos prototípicos y en la monitorización detallada del comportamiento de los participantes a través de un entorno de realidad virtual. No se trata, por tanto, de un producto comercial ni de un dispositivo que pueda adquirirse o utilizarse fuera de ese contexto experimental.
Más allá de su complejidad técnica, el valor del estudio reside en una idea clara y explícita: la tecnología debe adaptarse a la persona, y no al revés. No estamos ante un artilugio llamativo ni ante unas simples gafas inteligentes listas para el mercado. Estamos ante un ecosistema completo de asistencia, concebido como objeto de investigación, cuyo objetivo es extraer información de alto valor sobre percepción, aprendizaje y movilidad. Ese conocimiento es el que, en el futuro, debería servir para que los sistemas de asistencia a la movilidad que sí lleguen a desarrollarse como productos reales sean más eficaces, más intuitivos y, sobre todo, mejor alineados con la experiencia cotidiana de las personas ciegas.
Un sistema completo, no un accesorio aislado
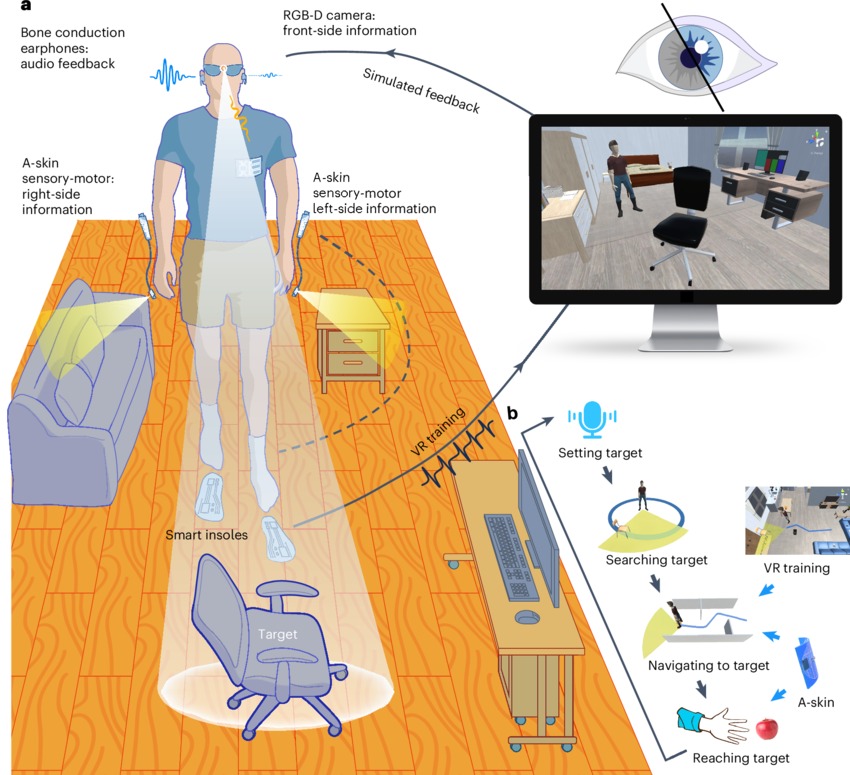
El planteamiento del equipo chino parte de una premisa fundamental: la movilidad no es un momento puntual, sino un proceso continuo que empieza antes de caminar, se desarrolla durante el desplazamiento y continúa después. Para cubrir ese ciclo completo, el sistema integra varios subsistemas que trabajan de forma coordinada:
• Un módulo de visión artificial RGB-D montado en unas gafas impresas en 3D
• Procesamiento local mediante Raspberry Pi 4, sin dependencia de la nube
• Audio espacializado mediante auriculares de conducción ósea
• Pieles electrónicas hápticas (A-skins) colocadas en las muñecas
• Plantillas inteligentes autoalimentadas para análisis de la marcha
• Una plataforma de entrenamiento inmersivo en realidad virtual
El resultado es un conjunto portátil de unos 200 gramos, pensado para ser usado durante periodos prolongados sin bloquear los sentidos naturales ni generar una sobrecarga cognitiva innecesaria.
Visión artificial con sentido práctico: menos es más
Uno de los errores clásicos de la visión artificial aplicada a la ceguera ha sido intentar reconocer absolutamente todo. Este sistema hace justo lo contrario.
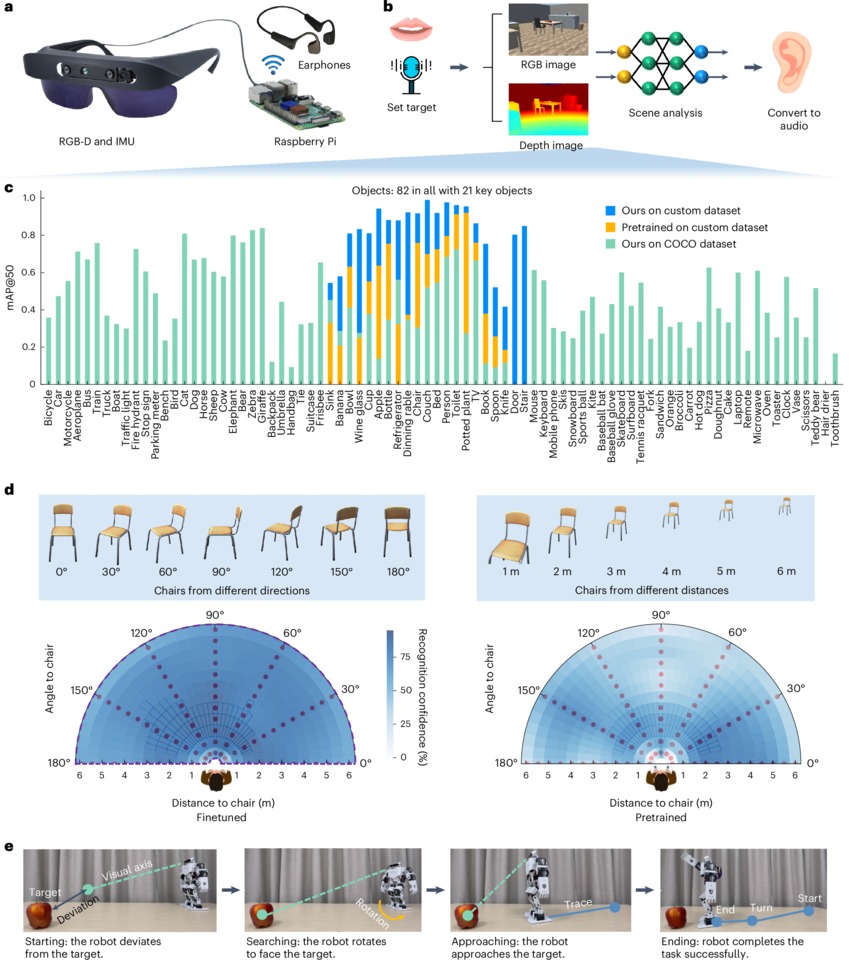
El modelo de inteligencia artificial ha sido entrenado específicamente para 21 categorías de objetos clave, seleccionadas por su relevancia real en la vida cotidiana: sillas, puertas, personas, mesas, camas, paredes, fregaderos, obstáculos a distintas alturas, entre otros. Esta decisión reduce de forma drástica el ruido informativo y permite:
• Respuestas más rápidas
• Mayor fiabilidad práctica
• Menor carga cognitiva para el usuario
El reconocimiento se apoya además en mapas de profundidad capturados por una cámara Intel RealSense D435i, lo que permite mantener una detección robusta desde distintos ángulos y distancias, incluso mientras la persona se desplaza.
La arquitectura de procesamiento imita, de forma deliberada, la percepción humana:
• Procesamiento denso para la zona central del campo visual
• Procesamiento rápido y disperso para la periferia
Esto se traduce en latencias de apenas 18 milisegundos para la información crítica, perfectamente alineadas con los tiempos de reacción humanos.
Navegación pensada para cuerpos humanos, no para robots
Caminar no es solo saber dónde está un objeto, sino cómo llegar hasta él sin romper la fluidez natural de la marcha. El sistema incorpora algoritmos de evitación de obstáculos diseñados específicamente para el movimiento humano, no para trayectorias robóticas.
Combina dos estrategias complementarias:
• Detección de obstáculos elevados o cercanos
• Identificación de obstáculos bajos, colgantes o a nivel del suelo
El entorno se segmenta dinámicamente y el sistema selecciona rutas que requieren la menor rotación corporal posible, favoreciendo una marcha más natural, suave y segura.
Los resultados hablan por sí solos:
• Reducción del 67 % en colisiones cuando se usan las A-skins
• Disminución del tiempo de navegación en un 24 %
• Trayectorias más cortas y eficientes
Tras el entrenamiento, el rendimiento se vuelve comparable —e incluso superior en algunos aspectos— al uso exclusivo del bastón blanco.
Audio que guía sin saturar
Otro de los grandes aciertos del diseño centrado en humanos está en cómo se transmite la información. El equipo comparó instrucciones verbales, sonidos tridimensionales y audio espacializado. El ganador fue claro.
El sistema utiliza señales sonoras direccionales, transmitidas por conducción ósea, que indican hacia dónde moverse sin describir verbalmente el entorno. El sonido no narra: señala. Esto permite:
• Orientación más rápida
• Menor tiempo de reacción
• Conservación total de los sonidos ambientales
La información auditiva se actualiza cada 250 milisegundos, suficiente para la navegación sin generar fatiga.
A-skins: cuando el tacto se convierte en percepción extendida
El elemento más innovador del sistema es, probablemente, el uso de pieles electrónicas elásticas, conocidas como A-skins. Colocadas en ambas muñecas —zonas de alta sensibilidad y bajo movimiento— integran actuadores vibratorios que proporcionan información inmediata y no verbal.
Las A-skins cumplen una doble función:
1. Durante la navegación, amplían el campo perceptivo lateral, detectando obstáculos fuera del eje central de la cámara.
2. Después, facilitan tareas de alcance y agarre, mejorando la precisión en distancias cortas.
No son simples avisadores: funcionan como una extensión sensorial del cuerpo, con tiempos de respuesta compatibles con la percepción humana.
Aprender sin miedo: entrenamiento inmersivo y progresivo
Uno de los mayores frenos a la adopción de nuevas tecnologías de asistencia es el aprendizaje. Para abordarlo, el sistema incorpora una plataforma de entrenamiento en realidad virtual, desarrollada en Unity, con escenarios realistas y dificultad progresiva.
Las plantillas triboeléctricas autoalimentadas capturan el patrón de marcha real del usuario y lo sincronizan con su avatar virtual, creando una experiencia corporal coherente. Además, las escenas se transforman de forma aleatoria para evitar la memorización mecánica.
El resultado es una curva de aprendizaje sorprendentemente corta:
• La mayoría de usuarios domina el sistema en 10–20 minutos
• La confianza al evitar obstáculos pasa del 60 % al 90 % tras el entrenamiento
Resultados medibles, personas reales
El estudio se realizó con 20 personas con discapacidad visual, sin experiencia previa en este tipo de sistemas, combinando pruebas en entornos virtuales, reales y comparaciones con robots humanoides.
Entre los resultados más relevantes destacan:
• Velocidad de marcha un 28 % mayor
• Reducción significativa de colisiones
• Puntuación de usabilidad SUS excelente al alcanzar 79,6/100, en el percentil 85
• Sensación subjetiva de control, seguridad y anticipación
No se trata de “ver”, sino de construir una percepción artificial que el cerebro pueda integrar de forma natural.
Un paso adelante con los pies en el suelo
Este trabajo no promete devolver la visión, y precisamente ahí reside su fortaleza. Ofrece algo más realista y valioso: autonomía, anticipación y confianza.
Desde Infotecnovisión creemos que su importancia no está solo en los números o en la sofisticación técnica, sino en el cambio de paradigma que representa. Demuestra que el diseño centrado en el ser humano, cuando se toma en serio, produce tecnología más usable, más ética y, sobre todo, más adoptable.
Aún existen limitaciones claras: tamaño de muestra reducido, pruebas principalmente en entornos controlados, desafíos en exteriores complejos y una transferencia comercial todavía lejana. Pero como investigación, el trabajo de Gu y su equipo marca un antes y un después.
La accesibilidad no se mide en algoritmos, sino en vidas que pueden moverse con mayor libertad. Y en ese sentido, este sistema no es solo un avance técnico: es una declaración de principios.
Recursos multimedia
Accede al minireportaje sobre esta investigación titulado “Gafas y sensores inteligentes para personas invidentes del canal alemán @DWTecnologiaymundodigital en español en YouTube.
Transcripción y descripción de imágenes:
“El video comienza mostrando a un hombre caminando por un pasillo utilizando unas gafas tecnológicas especiales y un bastón blanco. Una voz en off en español introduce el tema: “Estas gafas y sensores inteligentes podrían ayudar a las personas ciegas a moverse con mayor seguridad.”
La imagen cambia para mostrar un primer plano de las gafas, que tienen cámaras integradas. Un experto explica el funcionamiento técnico (traducido del inglés): “En la pequeña computadora hay algunos algoritmos que utilizamos; analizamos los datos y luego encontramos los objetos clave.” Mientras habla, vemos en pantalla una demostración visual de cómo el sistema identifica objetos en el entorno, como una silla, marcándolos con cuadros digitales.
El experto continúa: “Por ejemplo, si estoy interesado en una silla, el sistema me indica dónde está la silla y entonces me muevo hacia ella.” En el video, se observa a un usuario siguiendo las indicaciones sonoras del dispositivo. “Doy un paso y, de hecho, la información cambia porque mi posición ha cambiado”, añade el especialista, mientras la interfaz visual muestra cómo el mapa de objetos se actualiza en tiempo real según el movimiento del usuario.
A continuación, vemos a otro hombre probando el dispositivo en un entorno diferente. Un segundo testimonio (traducido del inglés) destaca la innovación del sistema: “La capacidad de una cámara montada en unas gafas para enviarte información tanto por los oídos como a través de retroalimentación háptica (vibraciones) es simplemente un paso adelante masivo.” Mientras escuchamos esto, la cámara enfoca los pequeños auriculares y los sensores táctiles que el usuario lleva en la piel o en el armazón de las gafas.
El video concluye mostrando nuevamente al usuario desplazándose con confianza en un espacio público, mientras la narración en español subraya que este sistema de parches y lentes equipados con IA permite evitar obstáculos tanto frontales como laterales, proporcionando una nueva capa de autonomía para las personas con discapacidad visual.
Autor: Ricardo Abad